
Imagine it’s Monday, 7:00 AM. Before heading to work, you want to enjoy a quiet cup of coffee. You turn on your coffee machine and suddenly hear a strange noise. Shortly after, an error message appears on the display. Looks like you’ll have to skip your coffee this morning.
In the industrial world, machine failures can lead to more than just a bad start to the day. One of our clients works in the steel industry. Occasionally, a critical component in the steel plant becomes overstrained. If this isn't detected in time, 180 tons of molten steel can spill onto the factory floor. Even if no one gets hurt, the product is ruined. Equipment suffers costly damage, and countless hours of intense labour are lost. The consequences of such failures can quickly amount to significant six-figure sums.
This scenario might sound familiar. Perhaps you also face severe or frequent machine failures in your daily work. The risk of production downtime, high damage costs, and other undesirable outcomes is elevated—after all, risk is defined as failure probability times failure cost. Naturally, this risk should be minimized.
The Impact of Predictive Maintenance
The good news is that a predictive maintenance strategy can detect and fix potential machine failures early on. If this predictive maintenance strategy is also data-driven, problems can be identified before they lead to major failures.
To implement this predictive, data-driven maintenance strategy, two approaches can be taken:
- Aggregating all data from a component or product to create a digital twin for a lifecycle model.
- Modelling process data to identify deviations from normal operations, allowing problems to be spotted before they escalate.
In this post, you'll learn how to effectively transition from failure patterns to a data-driven diagnostic tool using the second approach, which is often much more effective. And no, we’re not talking about an AutoML solution that generates useless data.
Mechanical components rarely fail without warning. In most cases, an event—like a minor surface defect on a rolling bearing—triggers a potential failure. In this case, the bearing doesn't run smoothly anymore.
However, it can take weeks before the machine completely fails and stops functioning. To act proactively, the time between the detected fault and the functional failure of the system must be long enough to allow for intervention.
To manage faults proactively, early detection of fault patterns is crucial. Subsequently, the fault must be localized quickly for prompt repair. Finally, the fault pattern should be associated with a failure mechanism. This helps predict how the fault will progress from detection, making future actions much more effective.
This concept is not new—Predictive Maintenance has been around for many years and traditionally involves considerable effort. However, today we have new possibilities. Modern machines are IoT-ready and can be networked, generating vast amounts of data that artificial intelligence can process automatically. This makes comprehensive machine monitoring feasible and Predictive Maintenance worthwhile in many cases.
To develop a data-driven diagnostic tool that enables Predictive Maintenance, data experts and process experts usually collaborate. Data experts have the necessary skills to model data and detect anomalies, while process experts understand machine behaviour. Only together can they develop a data-driven diagnostic tool—each expertise is essential in the development process.
However, this collaboration is often challenging: developing the diagnostic tool is rarely linear. Iterations, mutual learning, information exchange, scheduling meetings, and occasional delays (like vacations) can mean such projects take over two years to complete. This results in significant time, money, and resource losses. We aim to change that!
The Alpamayo DeepFMEA Framework
To overcome the lengthy collaboration challenges, we've automated the process between data and process experts as much as possible. As mentioned, both parties are crucial for creating a diagnostic tool that isn't a black box but provides meaningful and effective outputs. We've examined the workflow between them and identified several known steps on the data and process expert's side:
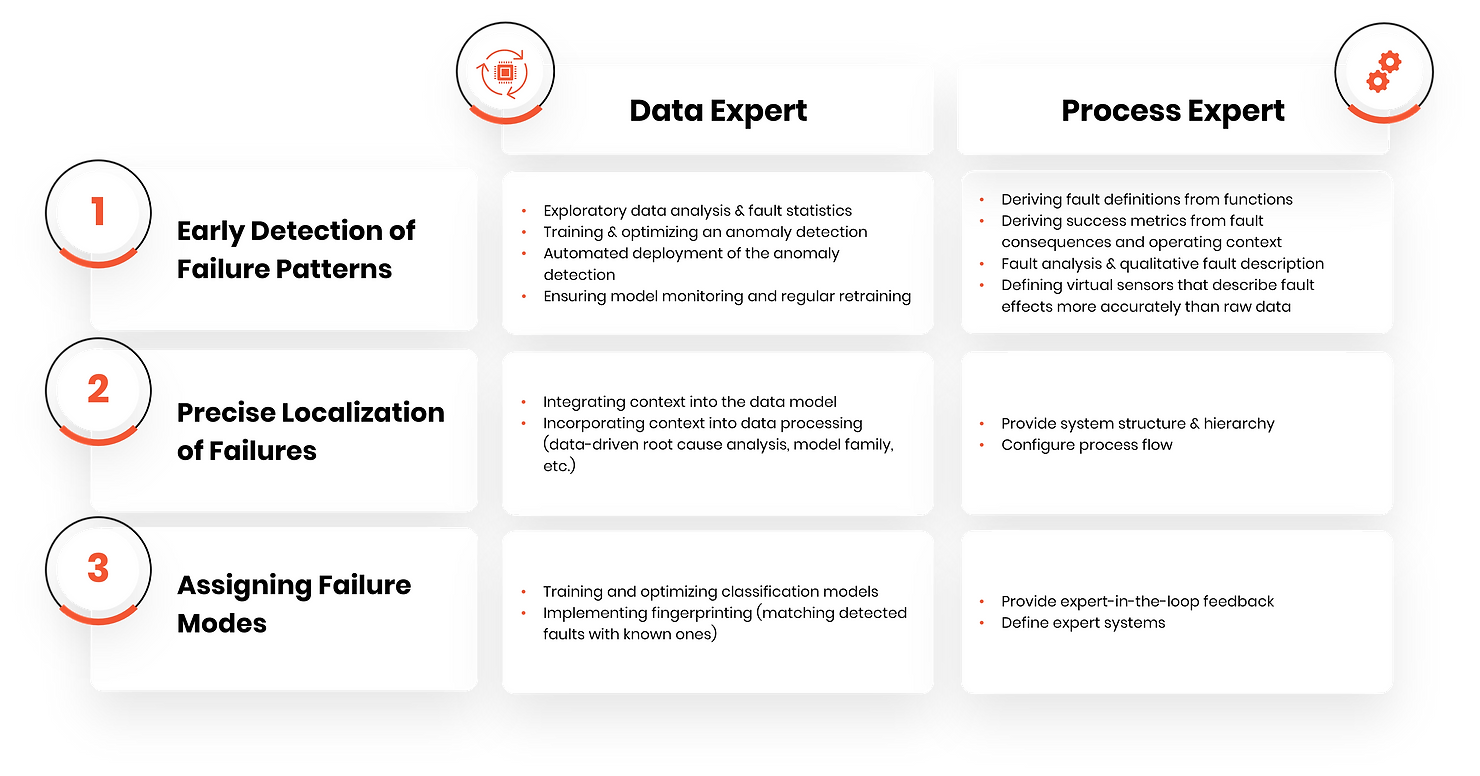
Functions, failure analysis, fault description, failure effects, system structure, and hierarchy are components of the FMEA: Failure Modes and Effects Analysis. Various software solutions exist for performing FMEA, and the underlying data model is not particularly complex. We can thus recognize a structured and established approach on the data expert's part. This is essential for our further steps—by understanding and identifying the data expert’s tasks and functions concerning the workflow, we can abstract, systematize, and automate them.
Using these insights, we developed DeepFMEA, a framework that significantly simplifies the development of data-driven monitoring and diagnostic tools.
This is neither an implementation of the Failure Modes and Effects Analysis nor a data-driven extension of the FMEA process. Instead, we drew inspiration from key FMEA characteristics:
- The data required for FMEA overlaps significantly with the information needed as domain knowledge in the development process.
- FMEA data is collected through a systematic process.
- A structured relational data model proposed by the analysis has been implemented by various vendors into database schemas.
DeepFMEA provides a standardized framework for developing and deploying data-driven PHM (Proactive Health Management) tools. This framework answers the question of how to transition from raw data and process expertise to a data-driven diagnostic tool. DeepFMEA is based on an abstract data model comprising multiple components. The data in this model can be used with various methods to develop data-driven PHM tools. These include monitoring, diagnostics, and prognostic methods.
Monitoring aims to detect anomalies without assigning failure modes. Our data model defines the relationship between the detection method, the system element, and the associated signals. This helps distinguish between relevant and irrelevant data for machine performance. Signals with no informational value regarding the system elements can be eliminated. Additionally, our model can be supplemented with virtual sensors as condition indicators, ensuring an effective monitoring process.
Diagnostics allows for localization and identification of failure modes. Building on monitoring, the embedded expertise and system understanding in the data model can be used to precisely locate fault patterns. Implementing our data model in a database, along with data pipelines making data accessible from their sources, creates a scalable data management system. This system can match fault incidents with respective failure modes, establishing a foundation for automatic monitoring, adjustment, and updating of data-driven models.
Prognostics often present a challenge in practice. The benefit of predictive statements is frequently limited. However, a data management system implementing the DeepFMEA data model can technically generate datasets enabling proactive maintenance. When a failure mode is thoroughly understood, experts can identify virtual sensors as degradation variables and link them with corresponding rules.
Our DeepFMEA framework enables the PHM tool development process to no longer rely on tedious exchanges between data and process experts, which often stall without achieving the desired results. We've created a framework that is application-independent, model-independent, and expandable, greatly simplifying the development of a data-driven diagnostic tool. Simultaneously, our framework accounts for the importance of data and process experts, making the prediction of potential machine failures possible.
Interested in the structure of our data model? Want to understand how to use our framework to improve your own use case? Download our DeepFMEA paper here:





